Le document ci-dessous est la quatrième partie du rapport du stage réalisé par Mathieu Passenaud auprès de mon service.
Comme son travail portait sur les problématiques de sauvegarde et d’archivage, ce quatrième chapitre mets en place des outils de haute disponibilité des bases de données MySQL.
La version PDF du document est disponible ici.
Chapitre 1– Introduction
Dans le cadre d’un processus de sauvegarde, il faut s’assurer que les données ne prennent pas trop d’espace mais aussi (le plus important) une réplication entière sur un autre support de l’intégralité des données.
1.1 But
Il faut toujours pouvoir assurer une réplication intégrale des données puisque le matériel, même le plus sophistiqué n’est pas à l’abris d’une panne ou un bâtiment n’est pas toujours sécurisé au mieux. Il faut donc avoir un doublon, si possible sur un autre lieu géographique. Lorsque les deux (ou plus) serveurs qui contiennent un SGBD plus la base de données fonctionnent en même temps, tout va pour le mieux. La synchronisation se fait en temps réel au fur et à mesure. Seulement, lors de l’ajout d’un nouveau serveur avec un SGBD et une base de données vide, la synchronisation doit se faire sans altérer les performances et assurer une haute disponibilité.
1.2 Principe
Chaque SGBD doit enregistrer toutes les opérations effectuées et lors de l’arrivée d’un nouveau SGBD transmettre toutes ces opérations à celui-ci. Le nouveau va donc se synchroniser en exécutant les opérations (à partir de l’emplacement où il s’est arrêté la dernière fois) pour être à jour par rapport au maître.
1.3 Mise en oeuvre
Les principaux SGBD contiennent des procédures de synchronisation entre bases de données différentes. La méthode à mettre en oeuvre pour MySQL sera présentée au chapitre 2.
Il existe aussi des drivers spécialisés qui se chargent de la réplication entre plusieurs bases de manière complétement transparente. Une de ces solution sera décrite au chapitre 3.
Chapitre 2 – Synchronisation avec MySQL
Documentation MySQL : http ://dev.mysql.com/doc/refman/5.0/fr/replication.html
2.1 Présentation
Plusieurs bases de données MySQL peuvent de synchroniser entre elles de manière complétement transparente. Une base est définie comme maître et une autre comme esclave. L’esclave cherchera toujours à être au même niveau que la maître.
2.2 Fonctionnement
Chaque machine exécutant un service MySQL a un numéro unique d’attribué. Dans l’esclave, on définit le maître avec une série de commandes SQL. Le maître garde dans un journal interne l’ensemble de commandes qui lui ont été soumises (insert, alter et update, le select n’affectant pas les données de la base).
L’esclave va lire le fichier journal du maître et exécuter les commandes pour être à jour. S’il a déjà exécuté une série de commandes, que le service est interrompu alors il reprendra là où il en était la fois suivante. La réplication est gérée en interne par le SGBD, aucune intervention de l’utilisateur n’est nécessaire dès lors que le processus est lancé.
Ces synchronisation sont gérées par des threads indépendants sur le maître et l’esclave. La disponibilité du maître est donc conservée (même si la charge du serveur est plus importante, la base de données reste toujours accessible).
2.3 Déploiement
Le but principal est d’avoir une réplication exacte des données sur plusieurs machines physiques distinctes. L’idéal est de profiter aussi du fait que 3 SGBD sont accessibles ce qui peut largement augmenter les performances du système. Ainsi, les 3 machines peuvent être entièrement exploitées pour accélerer le processus de sauvegarde plutôt que de garder une machine active et les 2 autres qui « dorment » en attendant de récupérer les informations sur le maître.
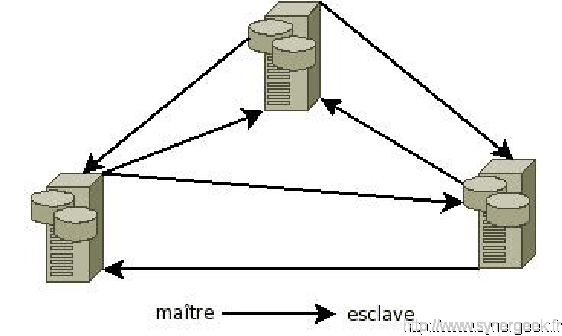
Avec un tel schéma, les 3 serveurs sont disponibles à n’importe quel moment et la réplication est assurée peu importe le serveur sur lequel on écrit. Si un des serveur n’est plus disponible la réplication se fait toujours puisqu’il existe toujours deux liens entre les serveurs. La disponibilité est donc toujours maximale.
2.4 Implémentation
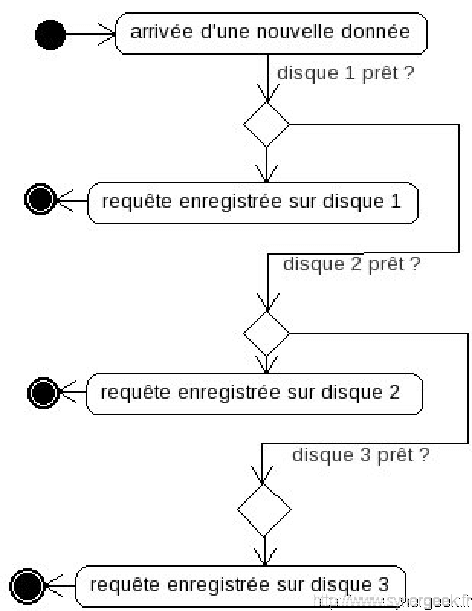
La synchronisation entre les différents SGBD se fait automatiquement et indépendamment de logiciel de déduplication. Il n’y a pas besoin de se soucier de l’emplacement sur lequel on enregistre la donnée.
Chapitre 3 – Synchronisation avec C-JDBC
C-JDBC est un driver de gestion de bases de données en grappe, complétement transparent pour l’utilisateur. Il a été récompensé au Linux World Product Excellence dans la catégorie « Meilleure solution en base de données ».
3.1 Présentation
C-JDBC est un driver de bases de données pour Java qui implémente la notion de clusters de machine et ce de manière complétement transparente. Les bases de données peuvent être de type différent et même au sein du même cluster les SGBD peuvent différer tant qu’il existe un driver JDBC pour accéder à la base.

3.2 Les différents niveaux
C-JDBC permet de faire une « pseudo » architecture RAID avec des bases de données. Trois niveaux sont implémentés :
3.3 Utilisation
C-JDBC s’utilise comme n’importe quel driver JDBC pour Java. Le principal avantage est qu’il n’y a pas besoin de réécrire une application existante. On se connecte donc avec un programme Java à une base de données virtuelle. Le concept de cluster de bases de données est complétement masqué ce qui permet d’éviter la modification d’un programme java existant.
(http ://c-jdbc.ow2.org/current/doc/userGuide/html/ar01s10.html)
3.3.1 RAIDb-1
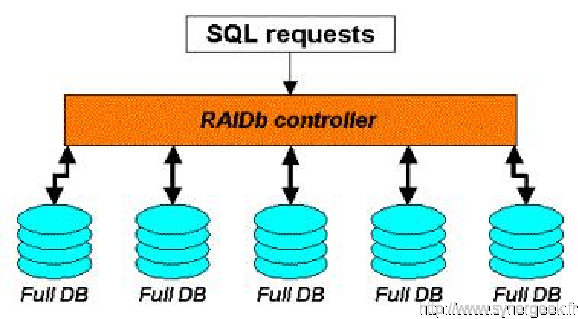
La réplication entre les différents serveur se fait intégralement. La duplication des données est assurée ainsi qu’une bonne disponibilité des serveurs, chacun ayant l’intégralité des données disponibles.
3.3.2 RAIDb-0
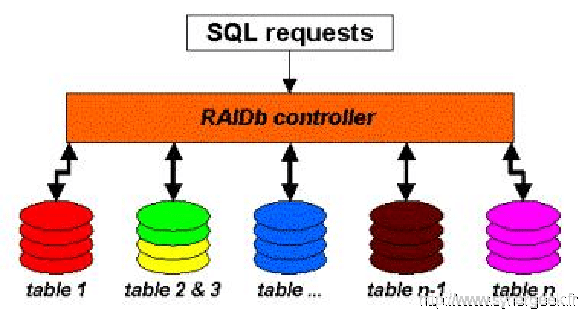
Une base de données est toujours découpée en différentes tables. L’idée est de séparer les différentes tables dans différentes bases de données pour assurer un accès très rapide aux données, cependant avec des requêtes plus complexes faisant appel à des jointures, le traîtement est plus coûteux en ressources machine.
3.3.3 RAIDb-2
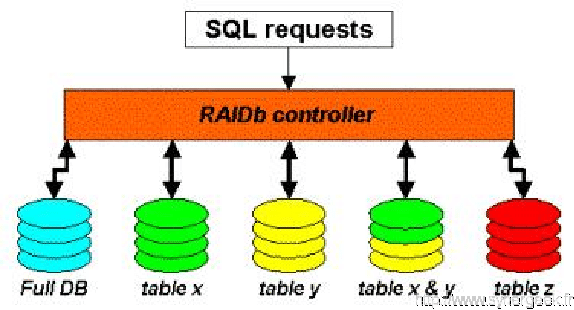
C’est un chemin intermédiaire entre le RAIDb-0 et le RAID-b1. La réplication est partielle tout en assurant une grande disponibilité des données pour l’utilisateur.
3.3.4 Combinaisons de plusieurs niveaux de RAIDb
3.3.4.1 RAIDb-1-0
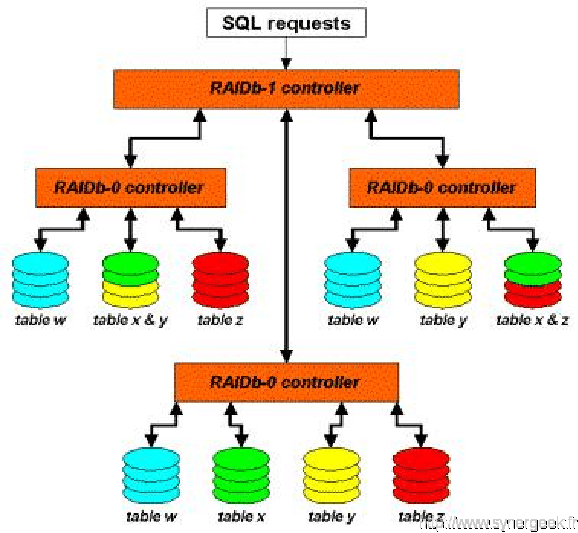
Le matériel nécessaire est beaucoup plus important, mais la réplication et la disponibilité des données sont combinés. Chaque contrôleur de RAIDb masque complétement son mode de fonctionnement ce qui ne change rien pour le contrôleur RAIDb-1, il ne verra que des bases de données virtuelles.
3.3.4.2 RAIDb-0-1
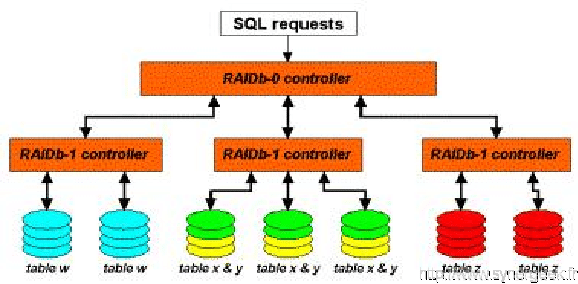
Tout comme précédemment, cette méthode permet la réplication intégrale de l’ensemble des données mais sous un schéma légèrement différent.


J’adore cette série d’article, très instructif ! Merci 🙂