
La déduplication des données consiste à identifier, dans les données, des séquences redondantes qu’il suffit ainsi de stocker une seule fois. La granularité d’un tel processus descend au niveau des blocs de données, éventuellement de tailles variables.
Les motivations sont multiples : gain d’espace disque consommé par les sauvegardes ou par des applications de production, réduction de la charge sur le réseau, allègement des procédures de sauvegarde ou, au contraire, des restaurations. Associées aux volumes des données, elles orientent le choix d’une technologie – déduplication à la source ou à la cible, à la volée ou en mode batch – dont chacune possède ses avantages et ses inconvénients.
Quoi qu’il en soit, toutes sont apparues très récemment, surtout chez les grands constructeurs comme EMC, HP ou NetApp, dont certaines annonces remontent à l’été dernier. Pourquoi seulement en 2008 ? D’abord parce que la déduplication consomme d’importantes ressources mémoire et CPU, désormais disponibles à moindre coût. Ensuite parce que le phénomène montant de la virtualisation des serveurs attise ce besoin. Les images des différentes machines virtuelles sont en effet souvent presque identiques dont aisément déduplicables.
http://www.indexel.net/materiels/les-multiples-avantages-de-la-deduplication-de-donnees.html
Le système ZFS de OpenSolaris ou Nexenta permets d’exploiter les technologies de déduplication et de compression en temps réel des données. Mais entre le discours et la réalité,quelles bénéfices une PME peux-elle espérer de ces technologies.
Au final, j’ai choisi de faire un test simple. J’ai monté une petite baie de stockage équipée de l’OS Nexenta Core. J’ai pris sur un véritable serveur de fichier 8.86Go de données et j’ai copié ces données dans la baie. En jouant avec les différentes options pour le système de fichier j’ai pu ainsi mesurer l’impact en capacité et performances qu’une PME peut concrètement espérer.
Voici mon jeu de données vu avec WinDirStat. On constate que une grande diversité de format et de tailles pour 30710 fichiers occupant un espace total de 7.1Go.
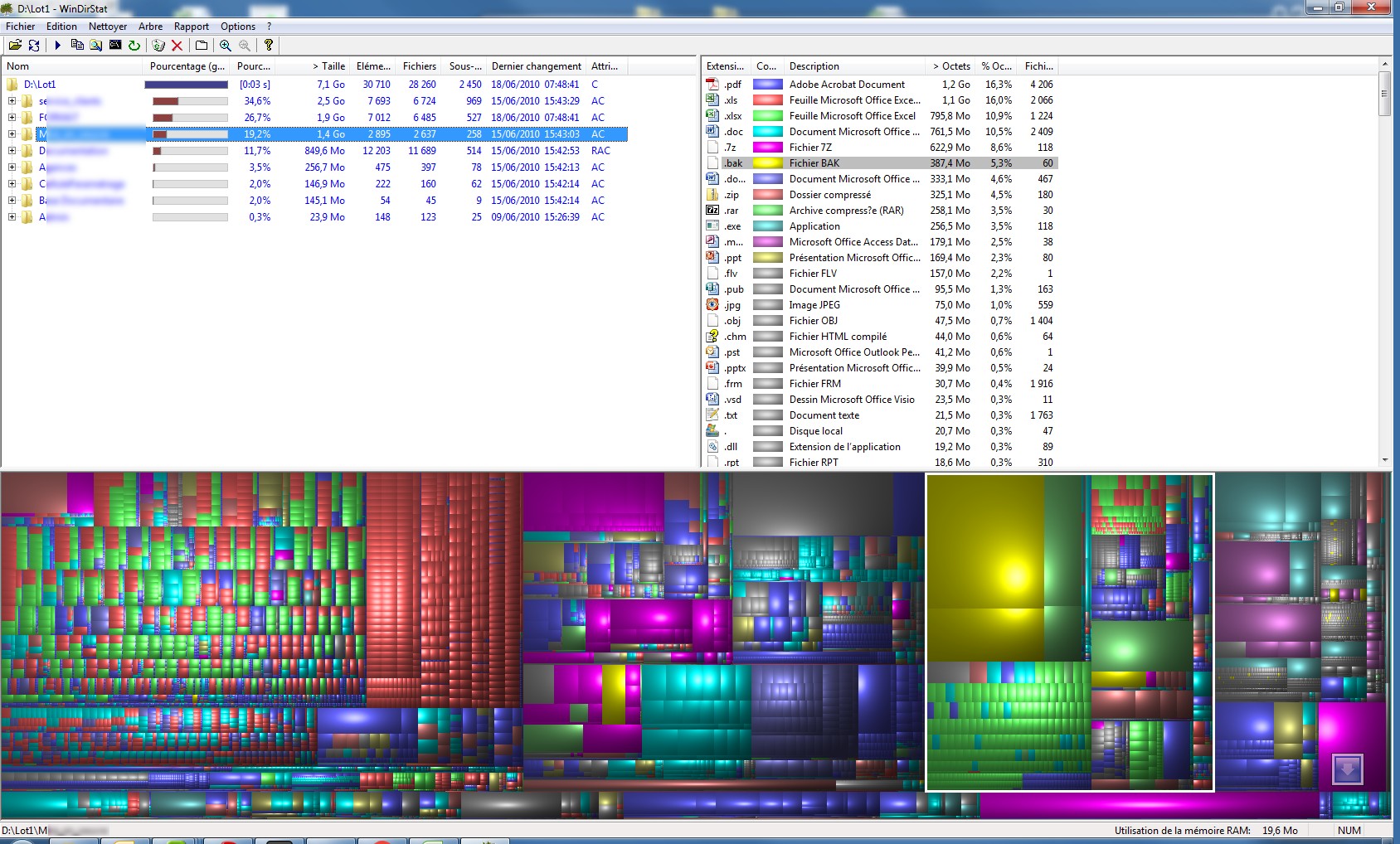
J’ai ensuite copié ces fichiers une première fois dans un espace de stockage en activant successivement les options de compression et/ou de déduplication.
pour rappel, avec ZFS, on utilise pour cela la ligne de commande suivante:
| Compression OFF | Compression ON | Déduplication OFF | Déduplication ON |
| zfs set compress=off data/test | zfs set compress=ondata/test | zfs set dedup=off data/test | zfs set dedup=on data/test |
Les premiers résultats sont résumé ci-dessous.
| C:off-D:off | C:on-D:off | C:off-D:on | C:on-D:on | |
| Espace% | 100% | 56% | 80% | 52% |
| Temps% | 100% | 65% | 55% | 57% |
Espace% représente le pourcentage d’espace occupé sur le disque par rapport au volume de données réel. On constate que les données sont facilement compressible (56%) ce qui est assez courant avec des fichiers bureautique. Par contre, les données sont faiblement redondantes puisque le déduplication ne permets de gagner que 20%. Finalement, en appliquant compression et déduplication, notre jeux de donnée ne requiert que 52% de sa taille déclarée pour son stockage dans la baie.
Temps% est le ratio de temps requis pour stocker les données dans la baie. On constate que si les algorithmes de compression et de déduplication charge fortement la consommation en CPU et RAM de la baie, ils réduisent considérablement les accès disques d’où un gain significatif en temps de stockage.
Pour tester l’efficacité de la déduplication, j’ai recopié le même jeux de données dans un second répertoire.
| C:off-D:off | C:on-D:off | C:off-D:on | C:on-D:on | |
| Espace% | 200% | 113% | 80% | 52% |
| Temps% | 200% | 130% | 121% | 92% |
On constate que la seconde copie du jeux de données est compressé une seconde fois à l’identique de la première copie (113% = 2×56%). Logiquement, la recopie prends également 130%=2×65% du temps requis pour copier le jeu de données sans compression.
Par contre, la déduplication joue parfaitement son rôle puisque le second jeu de données n’a aucun impact sur l’espace de stockage occupé (1jeu = 80% & 52% – 2 jeux = 80% & 52%). Par contre, le fait de stocker une seconde fois des données déjà présente dans la baie n’a que peu d’impact sur le temps de copie. La seconde copie est même légèrement plus rapide (92% < 2*57%).
En conclusion, la déduplication est extrêmement efficace puisqu’elle permet de supprimer l’archivage de données identiques. En fonction des performances des disques et de la capacité de traitement CPU/RAM de baie, cette option permet même de gagner en temps de stockage.
Sans aucun doute, il s’agit d’une réalité!
